定价
登录
Prompt
Attach MediaLibrary
Pick Character
1 / 4
💎 3 tokens
Demo Preview
Gpt Image 2
GPT 图像 2
GPT 图像 2 是 OpenAI 的下一代图像模型,专为需要可读文本、可信真实感以及在海报、模型、漫画和商业视觉系统中提供稳定结果的创作者设计。

GPT 图像 2 的优势
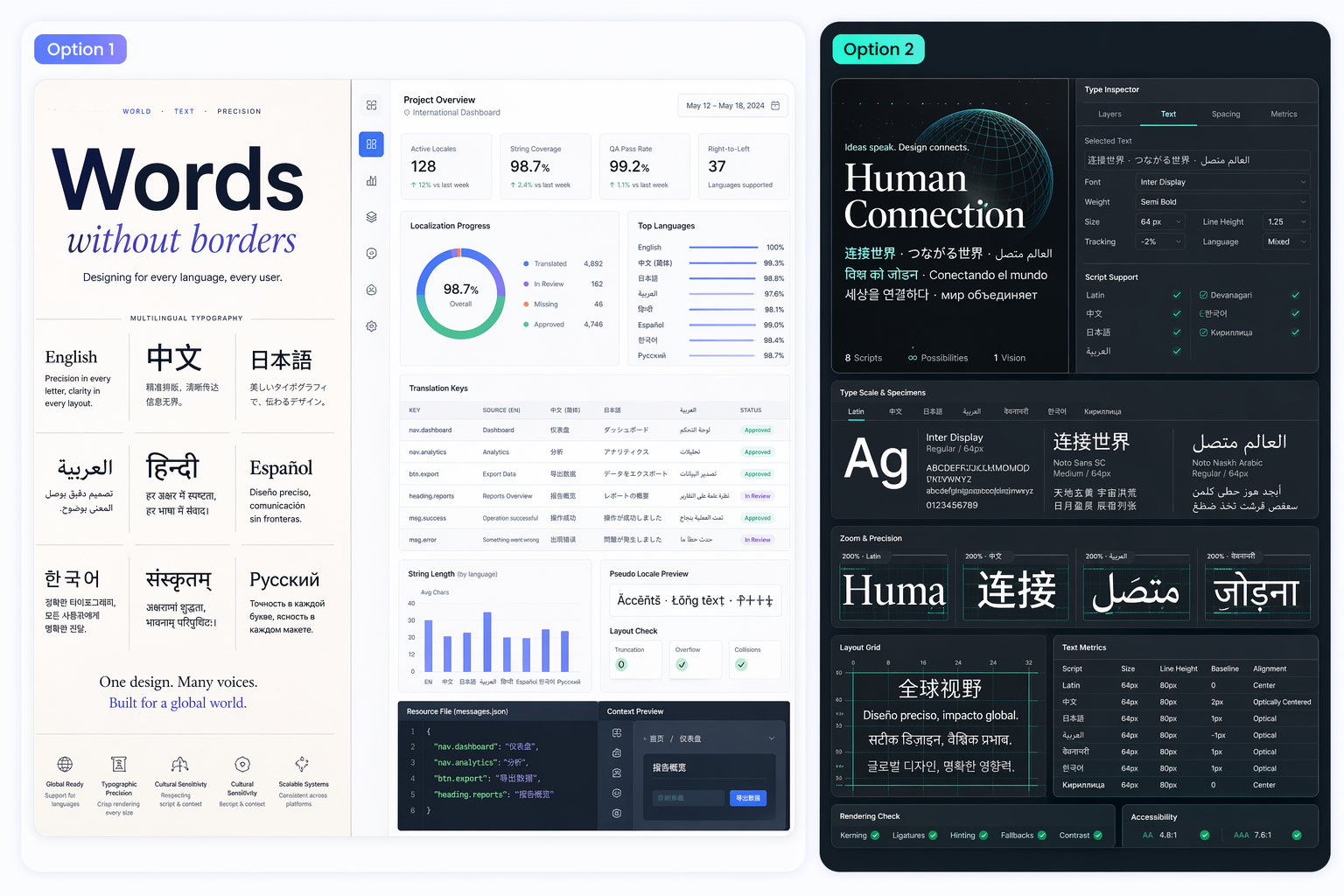
更清晰的文本渲染
GPT 图像 2 专为包含标签、标题、包装文案、标牌或界面文本的图像任务而设计。这使其在海报、菜单、UI 模型和多语言布局中更有用,而较弱的模型往往会扭曲字符或间距。
可信的逼真效果
该模型非常适合面向客户的视觉效果,因为光线、材质和场景细节更加可信。这在需要活动概念、编辑视觉效果或接近可发布作品的产品风格图像时非常有帮助。

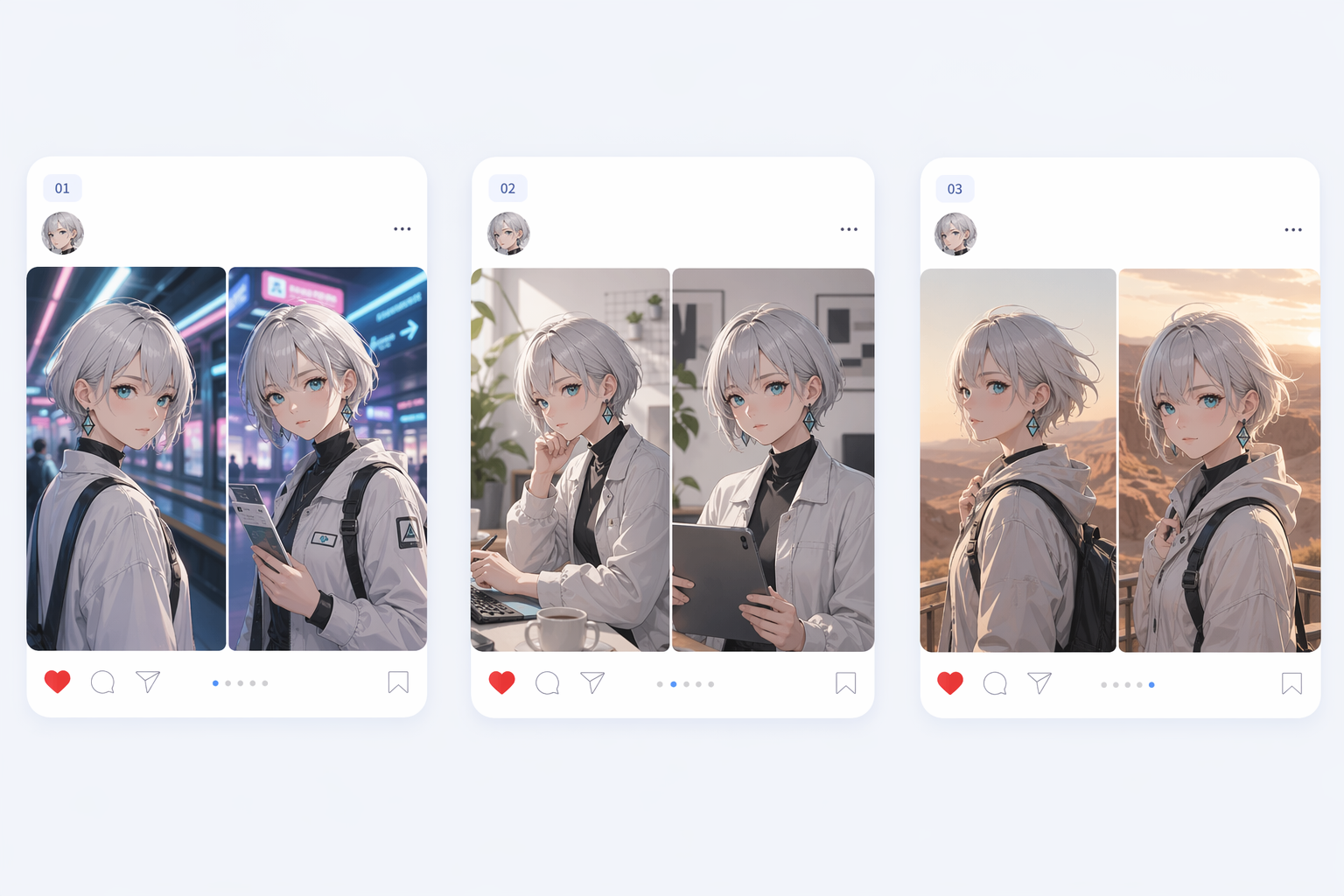
稳定的角色身份
GPT 图像 2 对于重复的视觉系统非常重要,因为面部、服装和比例在多个输出中更可靠地保持一致。这对于漫画、活动、目录以及任何依赖一致性的工作流程都很有价值。
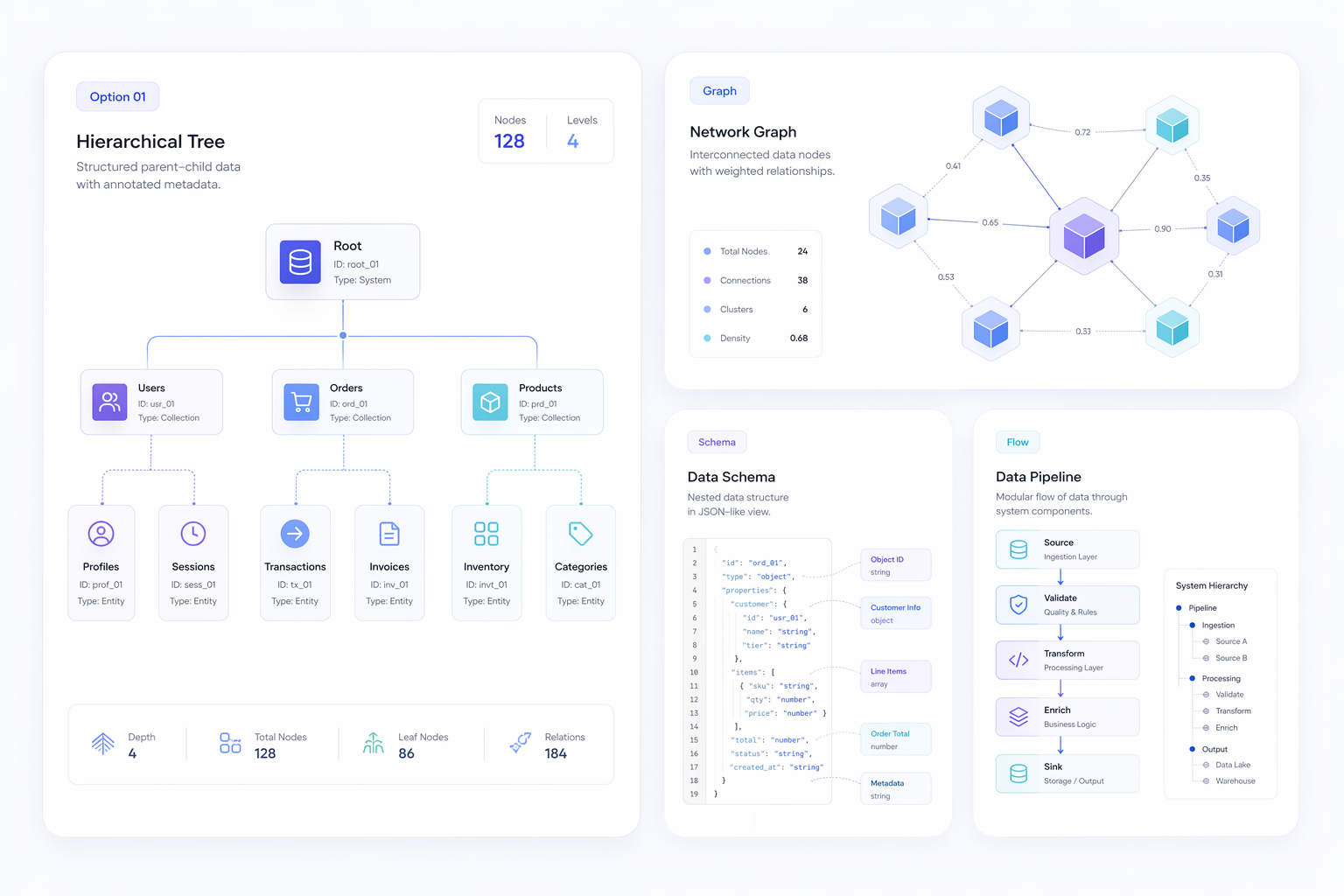
结构化场景逻辑
当图像包含多个相互依赖的元素(如标签、图表、UI 面板或信息密集型布局)时,该模型表现更强。更好的场景规划使这些输出更连贯,更容易在实际设计评审中使用。
使用场景
GPT 图像 2 的最佳使用场景
当项目需要文本保真度、布局控制、真实感或多个输出之间的视觉连续性时,GPT 图像 2 最具价值。
UI 模型
创建带有标签、面板和更清晰视觉层次的界面概念。
漫画
在多个面板和视觉故事序列中保持重复角色的稳定性。
图表
生成地图和结构化教育视觉效果,具有更连贯的布局逻辑。
GPT 图像 2 的核心能力
以文本为主的输出
适用于海报、菜单、包装、仪表板和界面预览,其中文本必须保持清晰可读。
逼真的场景细节
更好的光线、材质和对象连贯性使概念视觉效果更接近客户需求。
多图像稳定性
帮助在活动或故事中保持人物、服装和设计语言的一致性。
基于推理的构图
结构化场景(如地图、图表和密集布局)从更强的空间规划中受益。
如何使用 GPT 图像 2 获得更好的结果
01
定义输出类型
从实际任务开始,例如海报、UI 模型、产品照片、漫画面板或图表,以便 GPT 图像 2 知道需要保持哪些内容的稳定性。
02
提前描述文本和布局
如果图像需要标签、标题、价格或界面文案,请将这些要求放在提示的顶部,而不是在构图设置后添加它们。
03
优化一致性
运行后续迭代,锁定身份标记、间距和场景清晰度,直到输出足够强大,可以作为真实的创意资产进行评审。
团队为何关注 GPT 图像 2
减少文本校正
可读的排版是 GPT 图像 2 感觉更适合生产而非纯实验的最明显原因之一。
更连贯的复杂场景
地图、图表、仪表板和信息图表风格的场景在模型理解信息应该所在位置时受益。
更强的可重复性
如果团队需要多个相关输出而非一次性生成的幸运结果,一致性就成为核心购买理由。