定價
登入
Prompt
Attach MediaLibrary
Pick Character
1 / 4
💎 3 tokens
Demo Preview
Gpt Image 2
GPT Image 2
GPT Image 2 是 OpenAI 的次世代影像模型,專為需要可讀文字、逼真寫實效果以及在海報、模型、漫畫和商業視覺系統中穩定結果的創作者設計。

GPT Image 2 的改進之處
更清晰的文字渲染
GPT Image 2 專為包含標籤、標題、包裝文案、標誌或介面文字的影像任務設計。這使其在海報、菜單、UI 模型和多語言版面中更具實用性,避免較弱的模型經常扭曲字符或間距。
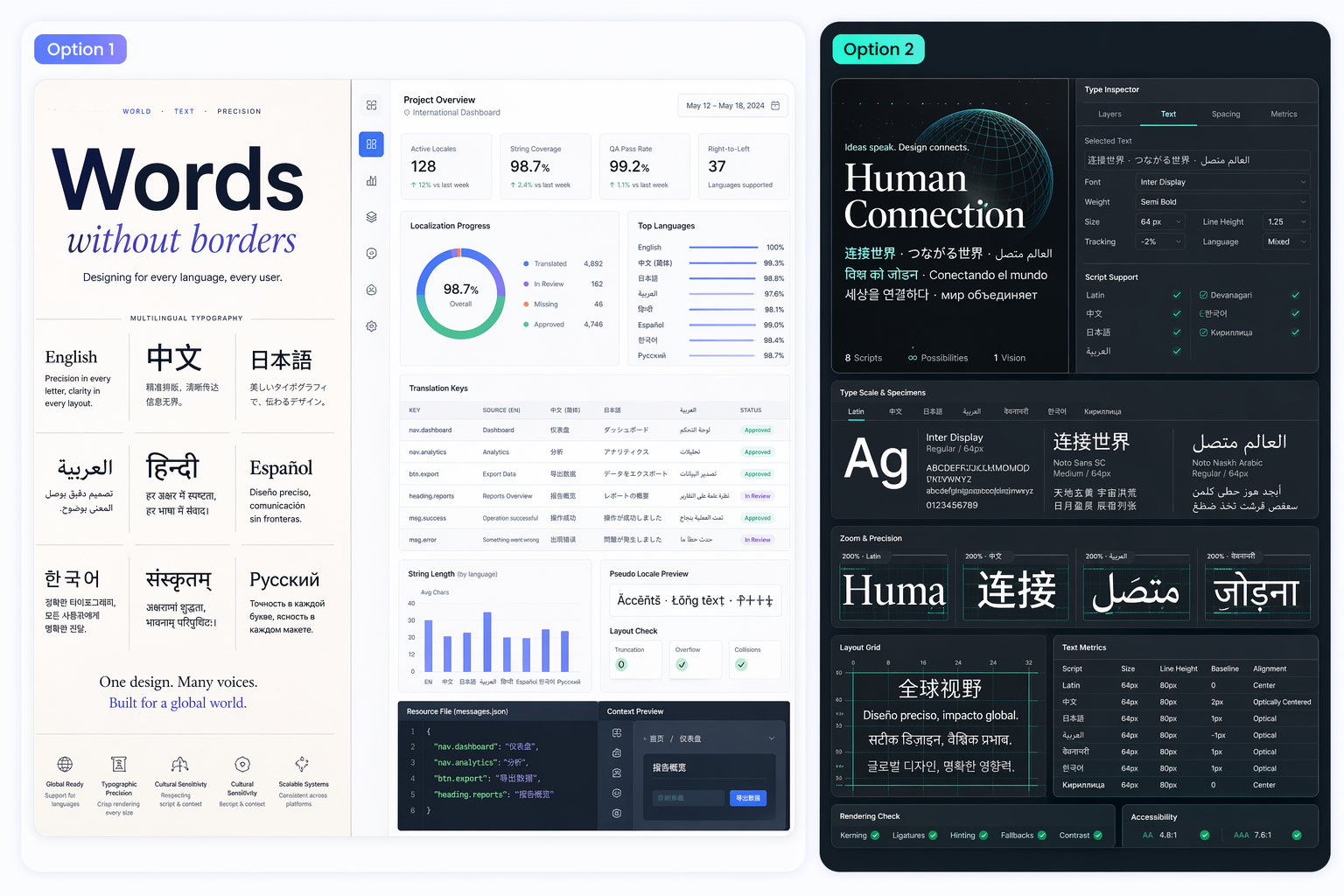
可信的寫實效果
該模型非常適合面向客戶的視覺效果,因為光線、材質和場景細節更具說服力。這在需要活動概念、編輯視覺效果或接近可發布作品的產品風格影像時尤為重要。

穩定的角色識別
GPT Image 2 在重複的視覺系統中尤為重要,因為面孔、服裝和比例在多個輸出中更可靠地保持一致。這對於漫畫、活動、目錄以及任何依賴一致性的工作流程都非常有價值。
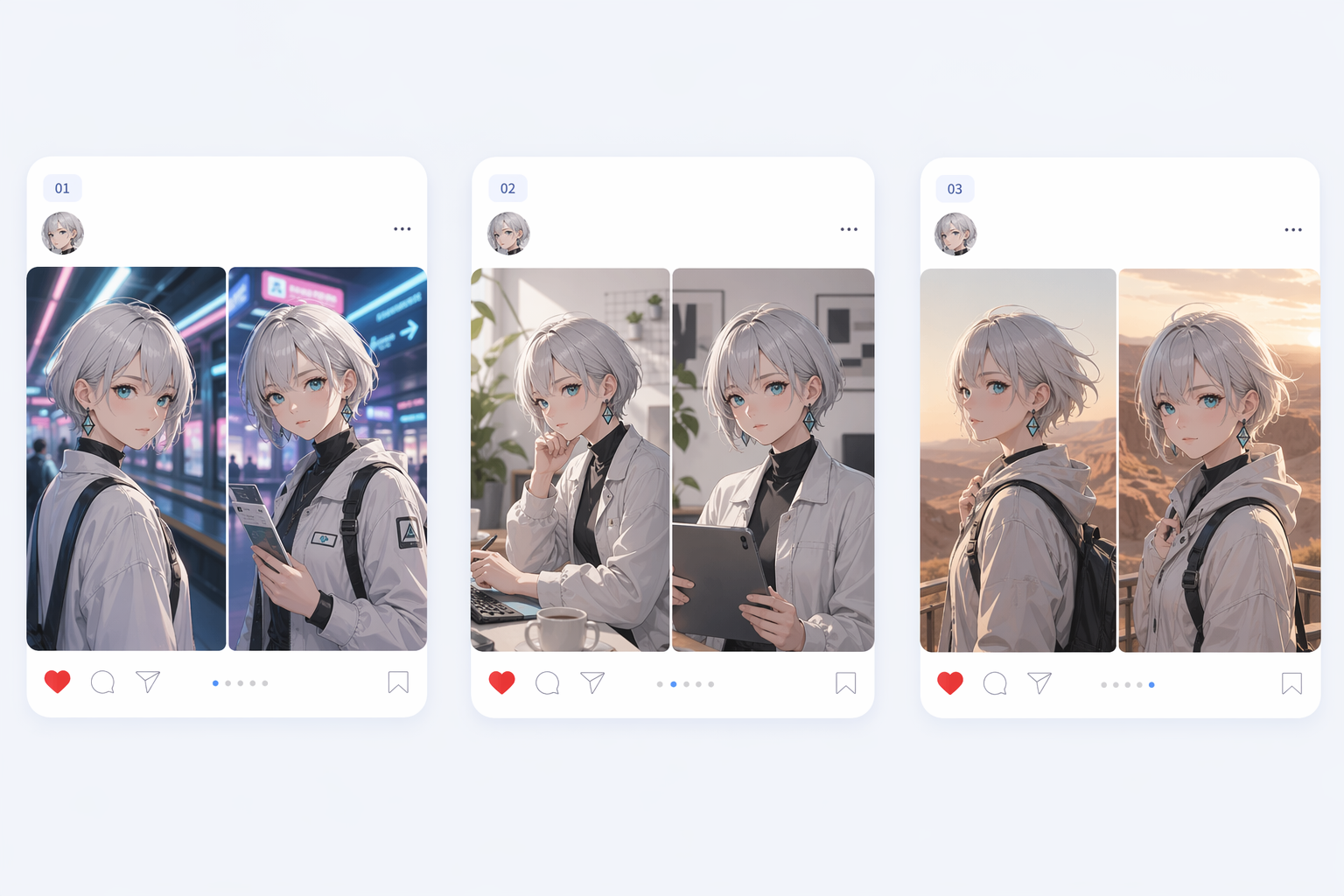
結構化場景邏輯
當影像包含多個相互依賴的元素(如標籤、圖表、UI 面板或信息密集的版面)時,該模型表現更強。更好的場景規劃使這些輸出更具連貫性,更易於在實際設計審查中使用。
使用案例
GPT Image 2 的最佳使用案例
當項目需要文字準確性、版面控制、寫實效果或多個輸出間的視覺連續性時,GPT Image 2 最具價值。
UI 模型
創建帶有標籤、面板和更清晰視覺層次的介面概念。
漫畫
在多個面板和視覺故事序列中保持重複角色的穩定性。
圖表
生成地圖和結構化教育視覺效果,具有更連貫的版面邏輯。
GPT Image 2 的核心能力
文字密集的輸出
適用於海報、菜單、包裝、儀表板和介面預覽,文字必須保持清晰可讀。
寫實場景細節
更好的光線、材質和物體連貫性使概念視覺效果更具客戶準備度。
多影像穩定性
幫助在活動或故事中保持人物、服裝和設計語言的一致性。
以推理為主導的組成
結構化場景(如地圖、圖表和密集版面)受益於更強的空間規劃。
如何使用 GPT Image 2 獲得更佳結果
01
定義輸出類型
從實際工作開始,例如海報、UI 模型、產品拍攝、漫畫面板或圖表,讓 GPT Image 2 知道需要保持穩定的內容。
02
提前描述文字和版面
如果影像需要標籤、標題、價格或介面文案,將這些需求放在提示的開頭,而不是在組成設置後再添加。
03
針對一致性進行優化
運行後續迭代,鎖定身份標記、間距和場景清晰度,直到輸出足夠強大,可以作為真實創意資產進行審查。
為什麼團隊注意到 GPT Image 2
減少文字修正
可讀的排版是 GPT Image 2 感覺更具生產導向而非純實驗性的最明顯原因之一。
更連貫的複雜場景
地圖、圖表、儀表板和資訊圖表風格的場景受益於模型理解資訊應該放置的位置。
更強的重複性
如果團隊需要多個相關輸出而非一次幸運生成,一致性成為核心購買理由。